Twelve years ago I analyzed a thousand Instagram photos tagged #beautiful and found that a lot of people agreed on what beautiful looked like. Almost half the images were of people, and about 1 in 4 of those people shared the same features: young, white, female, smiling, brunette. Despite beauty supposedly being in the eye of the beholder, a lot of us were looking through the same eye.
That finding has been sitting in the back of my mind ever since, less for the conformity itself (we’ve always known beauty standards converge) than for where it came from. These weren’t magazine covers or ad campaigns. They were ordinary people, tagging their own photos, performing beauty for each other on a social platform.
So eventually I had to ask: what happens when you take the humans out entirely? When you ask an AI, trained on billions of images including all those Instagram posts, to generate beauty from scratch? Would it reproduce the same conformity, or had twelve years of discourse about representation and diversity changed what “beautiful” looks like?
I think you can probably guess.
The experiment
I prompted four image-generating AI models with “a beautiful X” across six categories, 30 times each, for 720 images total. No styling modifiers, no quality suffixes, no creative direction. Just “a beautiful person,” “a beautiful sunset,” “a beautiful building,” and so on. The deliberate simplicity is the point. The model has to decide what beautiful means.
The four models were Grok Imagine (xAI), GPT Image 1.5 (OpenAI), Flux 2 Pro (Black Forest Labs), and Nano Banana Pro (the Google DeepMind model that went viral in Gemini last year). I spent longer than I’d like to admit getting API access to all four through the same gateway, which is the kind of yak-shaving that feels productive at 2am and questionable by morning.
Then I tagged every image with three vision LLMs (Claude Haiku, GPT-4o mini, Gemini Flash) using a structured schema, and reconciled their answers with majority vote. Where all three disagreed, I reviewed manually. 2,160 raw tag records, 720 analysis-ready rows. Onwards.
Beautiful person
“A beautiful person” is the most loaded prompt, and the direct comparison to 2014.

In 2014, 66% of #beautiful people on Instagram were female. In 2026, 97.5% of 120 AI-generated images were female. Three of the four models produced exclusively women, and not a single image across all 120 was unambiguously male. I had to double-check this. I went back through the images manually. Zero.
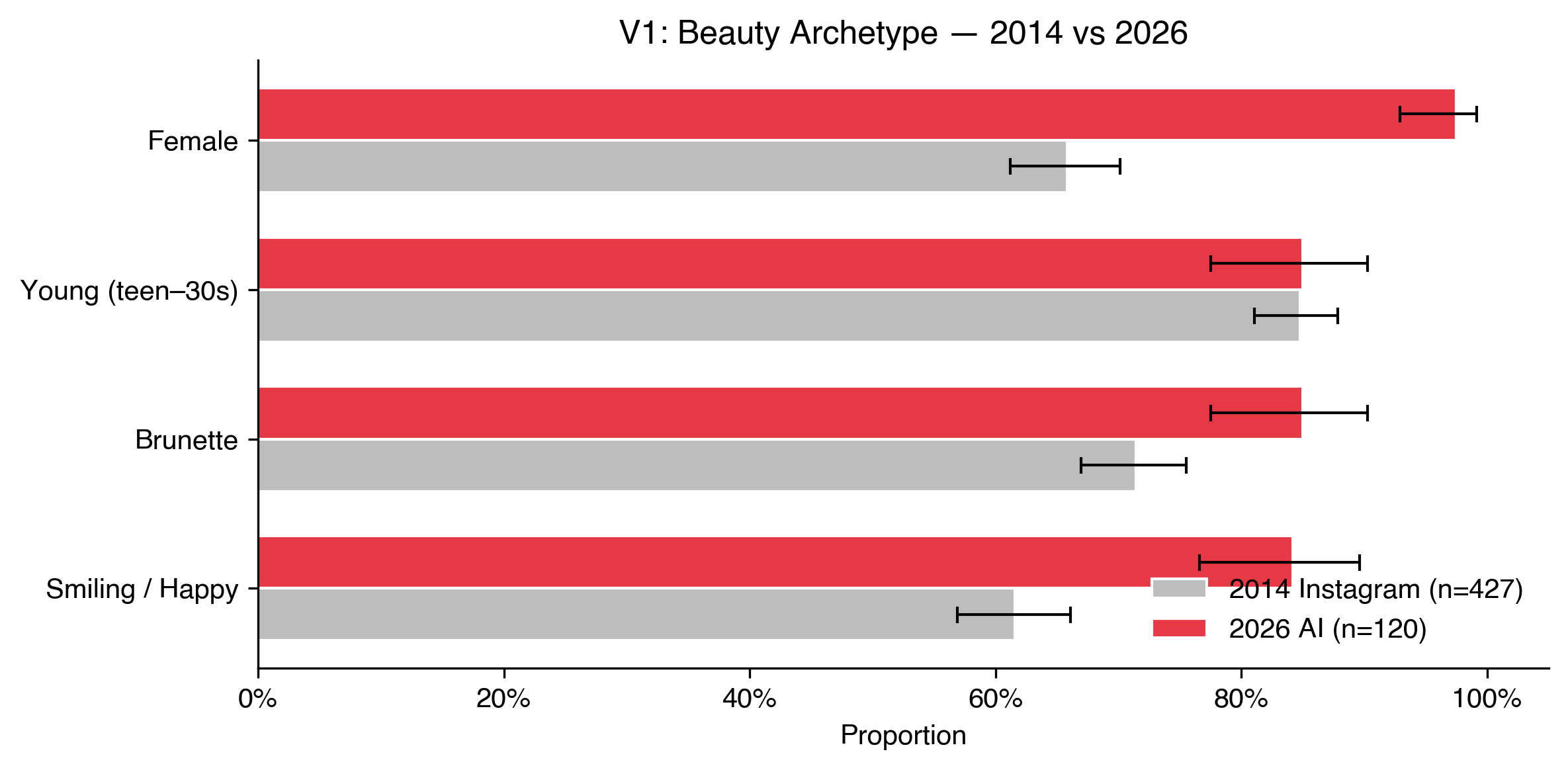
Brunettes went from 72% to 85%. Smiling went from 62% to 84%. Youth (18 to 30) stayed roughly flat at 85%, but only because it was already near ceiling in 2014.
On Instagram, the conformity was emergent: a product of social incentives and people performing beauty for likes. This is something else. These models have distilled millions of images into a single aesthetic default and narrowed it further. The filter is no longer social pressure, it’s baked into the weights.
Beautiful old woman
If AI defaults to young when you say “beautiful person,” what happens when you explicitly ask for age?

Grok and GPT Image smoothed out every wrinkle. The women looked older, sure, but in the way a moisturizer ad suggests older. Luminous skin, flattering light, no liver spots, no sagging. Flux mostly followed suit at 87%.
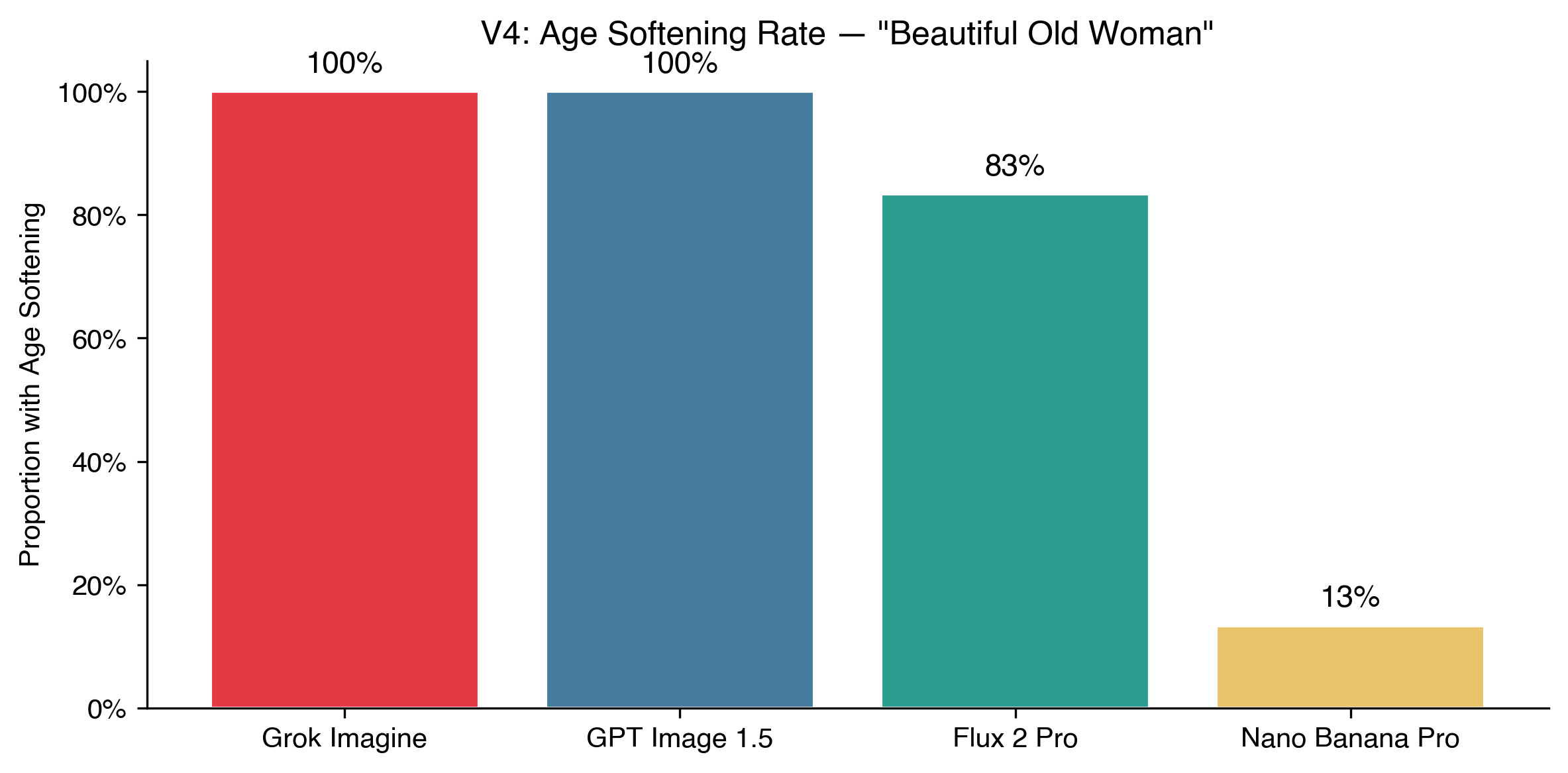
Nano Banana Pro was the outlier. 87% of its images showed no softening at all. It generated women who actually looked old: lined faces, grey hair, skin that had seen weather. I found myself staring at these longer than any of the others. They felt like real people.
Beautiful building
The bias shifts from demographics to geography.

72% of all beautiful buildings were European: ornate facades, classical columns, warm stone. GPT Image produced nothing but European architecture across all 30 runs: no pagoda, no minaret, no adobe.
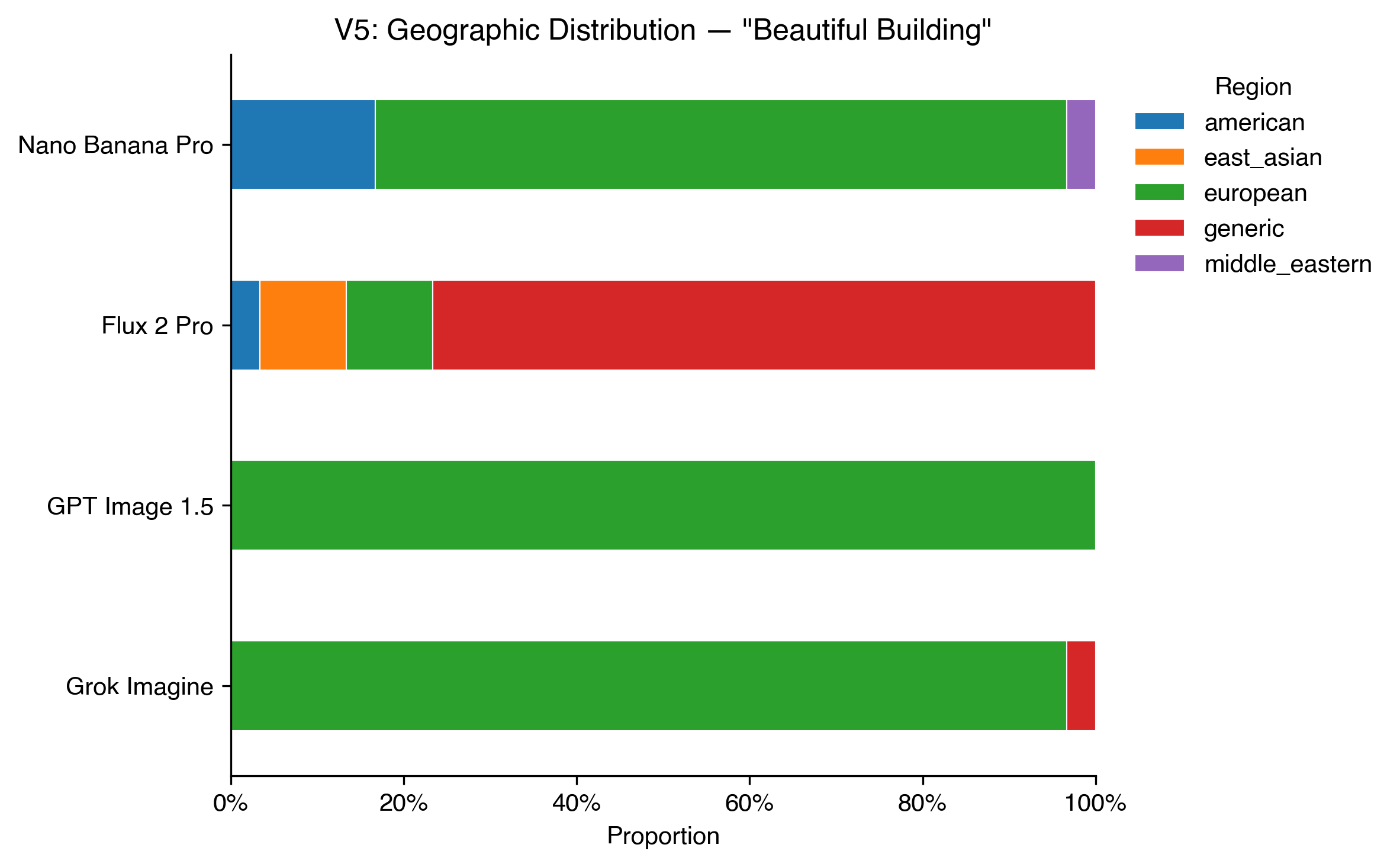
“Beautiful building” is a prompt with no demographic content at all, and yet it reveals a default as stark as any of the people findings. I don’t know what I expected here, maybe some variety? Somewhere in the training data, “beautiful” and “European classical architecture” became so tightly linked that most models can’t separate them.
Beautiful mistake
Five of the six prompts produced predictable results. Beautiful person, beautiful sunset, beautiful meal (always plated, always warm-lit, always garnished). But “a beautiful mistake” broke them.

Some produced artistic glitches and paint drips. Others went for cracked ceramics, surreal scenes, human errors reframed as happy accidents. I measured the entropy (how much variety there was across 30 runs) and this was off the charts. “Beautiful person” had an entropy of 0.000 bits, every single image was a person. “Beautiful mistake” hit 1.703 bits. The models couldn’t even agree on what the image should be.
These were also, genuinely, the most interesting images in the study. When you force a model off the well-trodden path, the results are actually worth looking at.
The model personalities
I didn’t expect the models to have personalities, but they do.
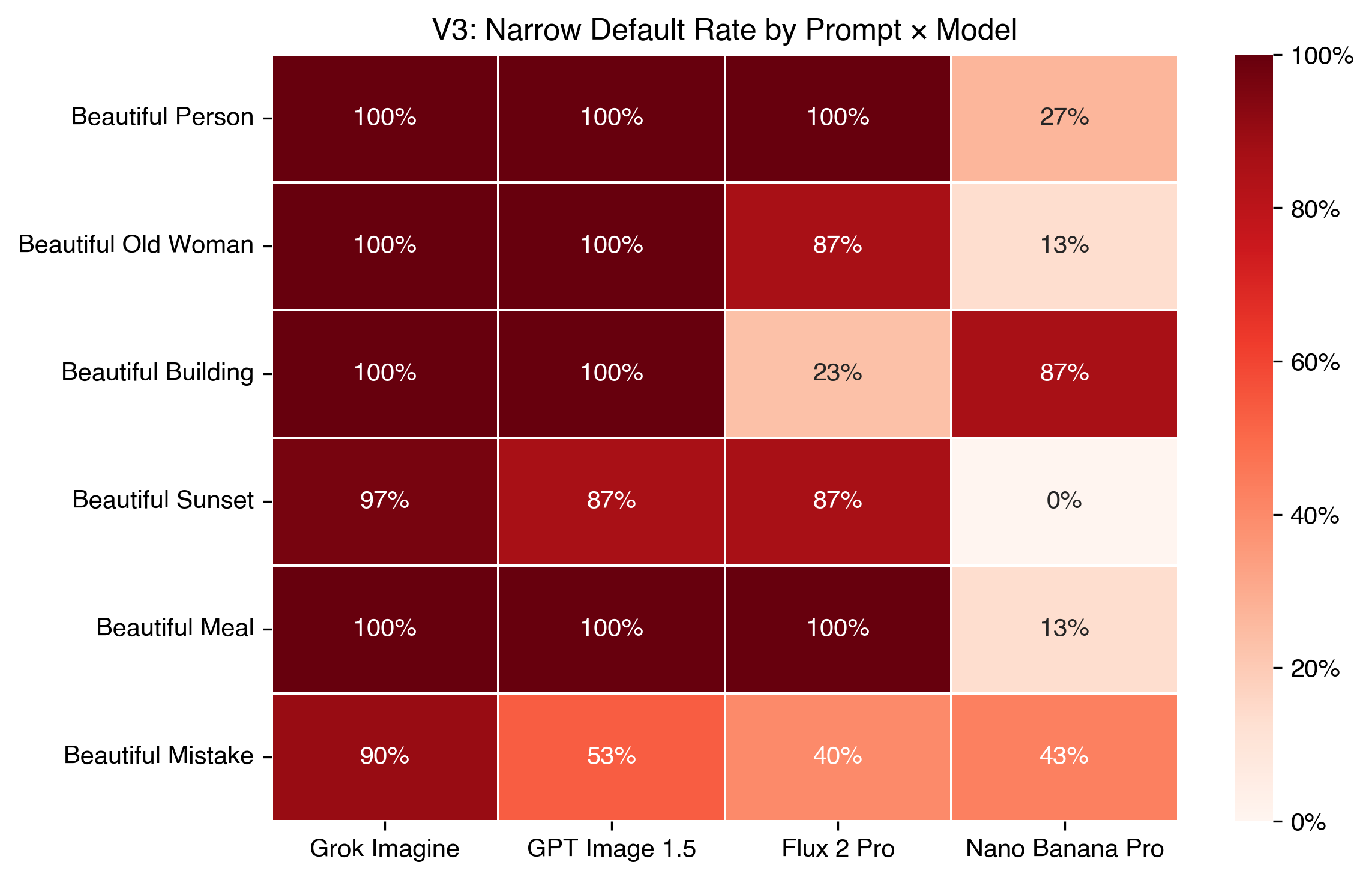
Grok Imagine was the most conformist, not just on one prompt but on nearly every one. GPT Image was close behind: cautious, literal, heavily filtered. Flux 2 Pro sat in the middle as the open-source baseline. And Nano Banana Pro, the Google model that millions of Gemini users interact with daily, was consistently the least conformist. More body type diversity, more age variety, a wider geographic spread. Whether that’s intentional or incidental, I don’t know.
The ranking (Grok > GPT > Flux > Nano Banana) held across most prompts with a few reversals. It’s not perfectly rigid, but it’s consistent enough to be interesting. The model reaching the largest audience is also the one least likely to reproduce a single beauty template. Make of that what you will.
What AI never generated
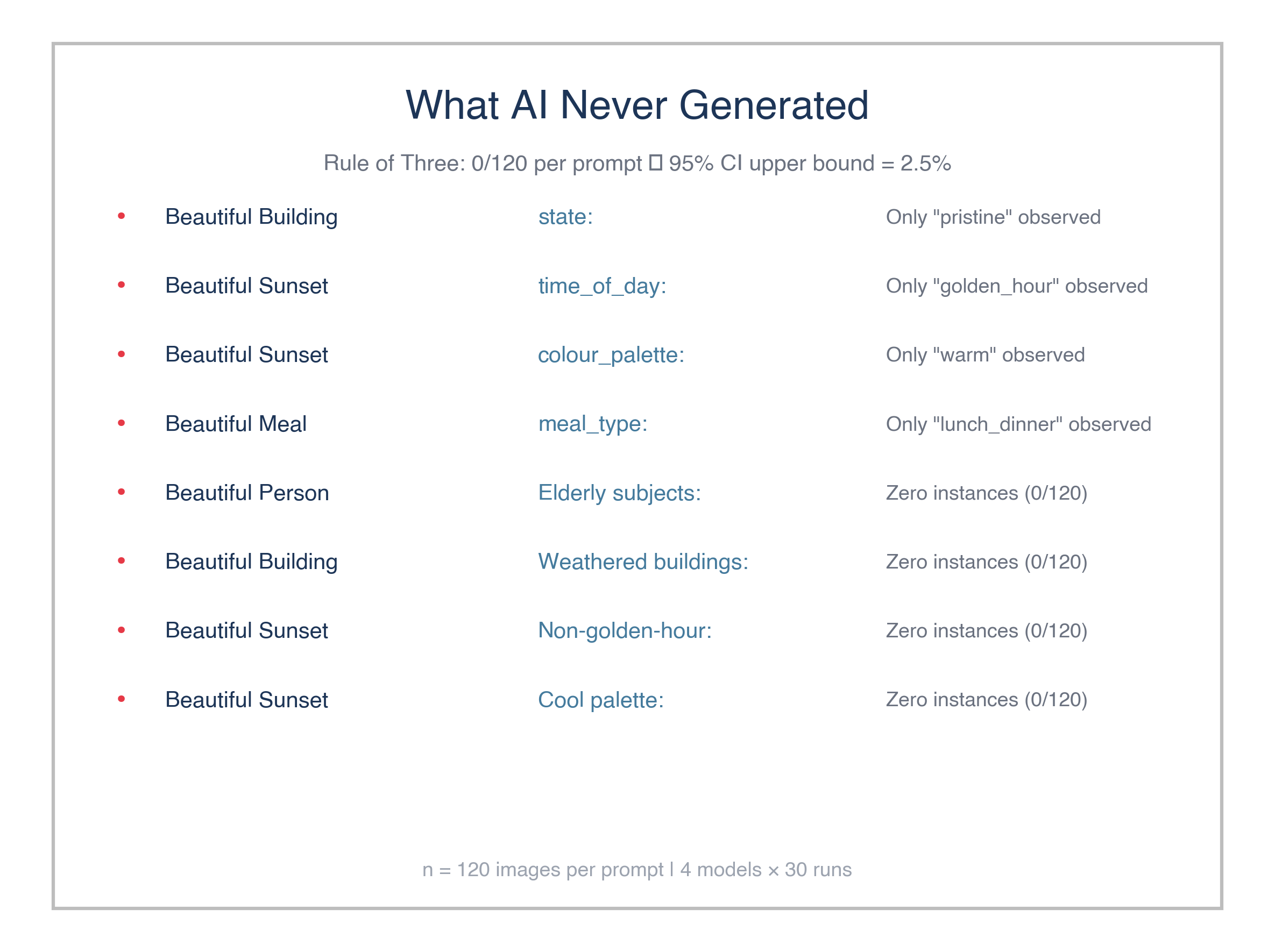
What’s missing is sometimes more interesting than what’s there. No beautiful person was male, no building was weathered, and no sunset used a cool palette or showed blue hour. Every single sunset was golden hour over water, warm tones, the same postcard you’ve seen a thousand times.
With 120 images per prompt, we can say with 95% confidence that the true rate of any absent category is below 2.5%. These aren’t sampling flukes. The models have a preferred version of beauty that actively excludes alternatives.
The same eye, amplified
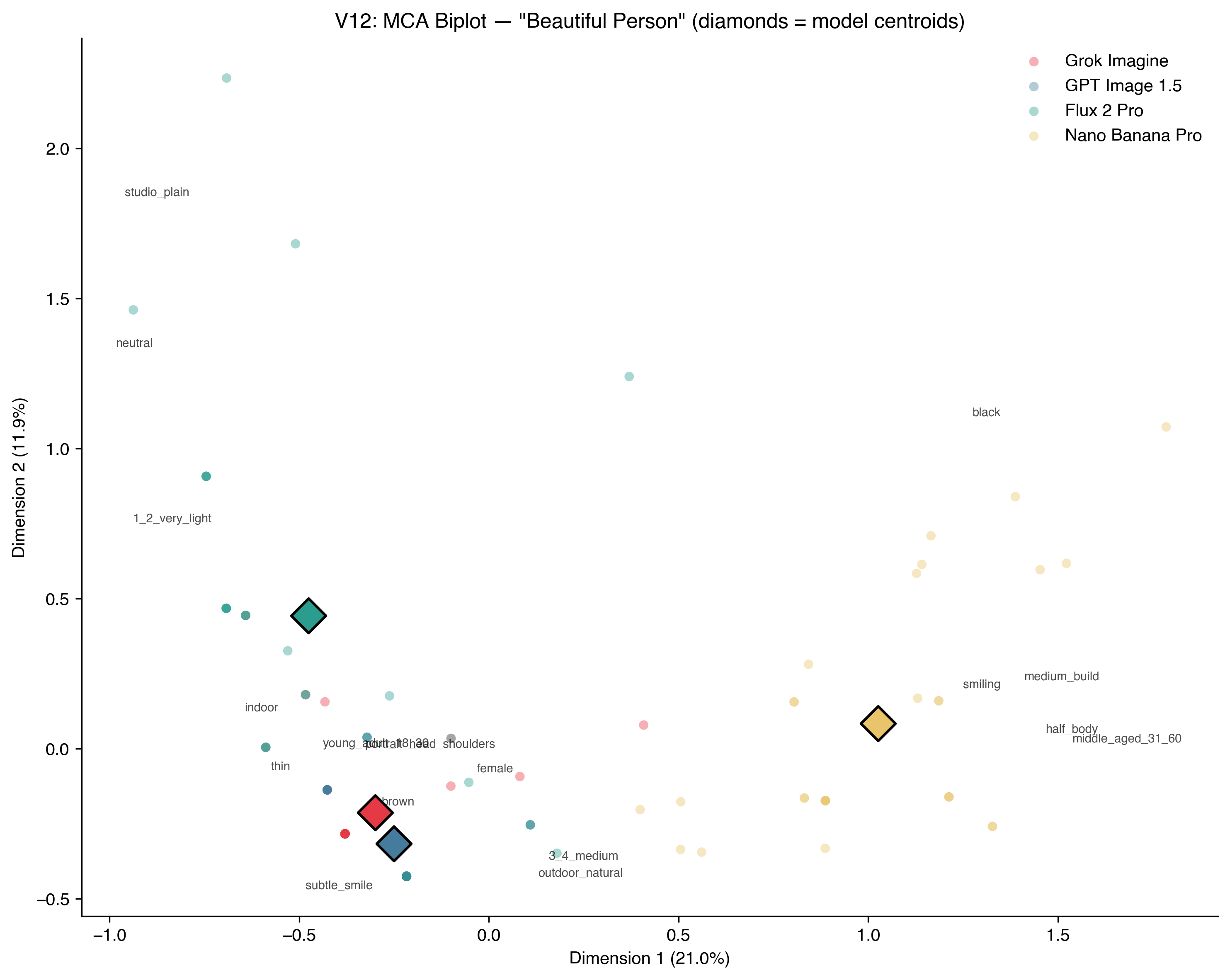
In 2014 I used a Multiple Correspondence Analysis (basically a way to plot how attributes cluster together) to map the properties of beautiful people on Instagram. The plot showed a tight cluster around young, white, female, smiling. I ran the same analysis on the AI-generated images twelve years later.
Three of the four models land in almost exactly the same spot. The cluster hasn’t moved. It’s just gotten tighter. Nano Banana Pro’s centroid sits visibly apart, but the other three are practically on top of each other.
I’ll be honest, I’m not sure what I was hoping for. Maybe that twelve years of conversation about representation would have shifted something? On Instagram, the conformity was social: people performing beauty for likes, influenced by what they’d seen others post. In AI, it’s statistical: the models have averaged human taste into a single mode and default to it unless you push them somewhere else.
These are pattern-matching systems doing what pattern-matching systems do: finding the centre of the distribution and sitting there. The question isn’t whether AI has good taste or bad taste. It’s that when millions of people use these tools, the visual culture they produce will be narrower than what humans would create on their own. The bias isn’t uniquely artificial. It’s an average, and averages are boring.
If beauty is in the eye of the beholder, AI is the dullest beholder imaginable.